

spiderFile模块简介
baidu_sy_img.py: 抓取百度的高清摄影图片。
baidu_wm_img.py: 抓取百度图片唯美意境模块。
get_photos.py: 抓取百度贴吧某话题下的所有图片。
get_web_all_img.py: 抓取整个网站的图片。
lagou_position_spider.py: 任意输入关键字,一键抓取与关键字相关的职位招聘信息,并保存到本地文件。
student_img.py: 基于本学校官网的url漏洞,获取所有注册学生学籍证件照。
JD_spider.py: 大批量抓取京东商品id和标签。
ECUT_pos_html.py: 抓取学校官网所有校园招聘信息,并保存为html格式,图片也会镶嵌在html中。
ECUT_get_grade.py: 模拟登陆学校官网,抓取成绩并计算平均学分绩。
github_hot.py: 抓取github上面热门语言所对应的项目,并把项目简介和项目主页地址保存到本地文件。
xz_picture_spider.py: 应一位知友的请求,抓取某网站上面所有的写真图片。
one_img.py: 抓取one文艺网站的图片。
get_baike.py: 任意输入一个关键词抓取百度百科的介绍。
kantuSpider.py: 抓取看图网站上的所有图片。
fuckCTF.py: 通过selenium模拟登入合天网站,自动修改原始密码。
one_update.py: 更新抓取one文艺网站的代码,添加一句箴言的抓取。
get_history_weather.py: 抓取广州市2019年第一季度的天气数据。
下载地址:https://github.com/yhangf/PythonCrawler
未经允许不得转载:PythonOK » PythonCrawler: 用 python编写的爬虫项目集合

 【Python教程】《零基础入门学习Python》最新版(小甲鱼)
【Python教程】《零基础入门学习Python》最新版(小甲鱼) 玩转年薪50W从零基础到量化工程师进阶篇
玩转年薪50W从零基础到量化工程师进阶篇 PythonABC 小伙伴们,跟我一起从零开始学Python吧
PythonABC 小伙伴们,跟我一起从零开始学Python吧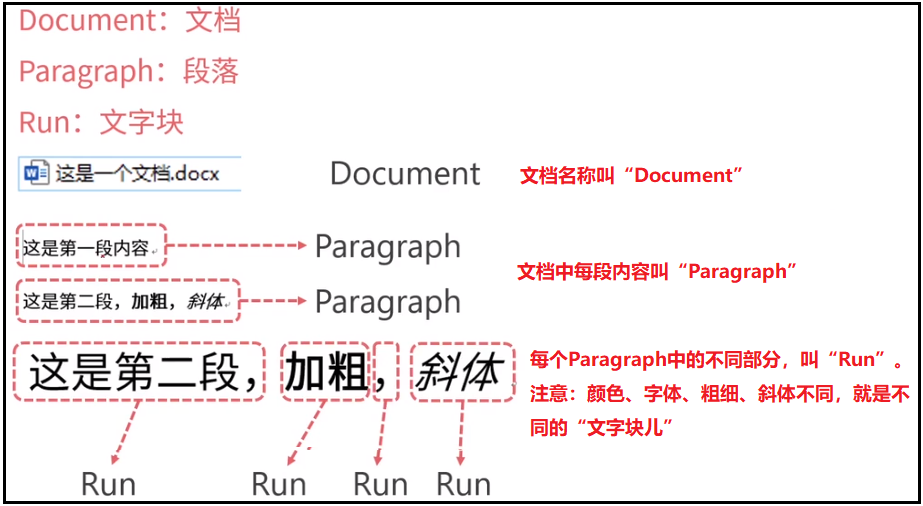 python使用python-docx操作word
python使用python-docx操作word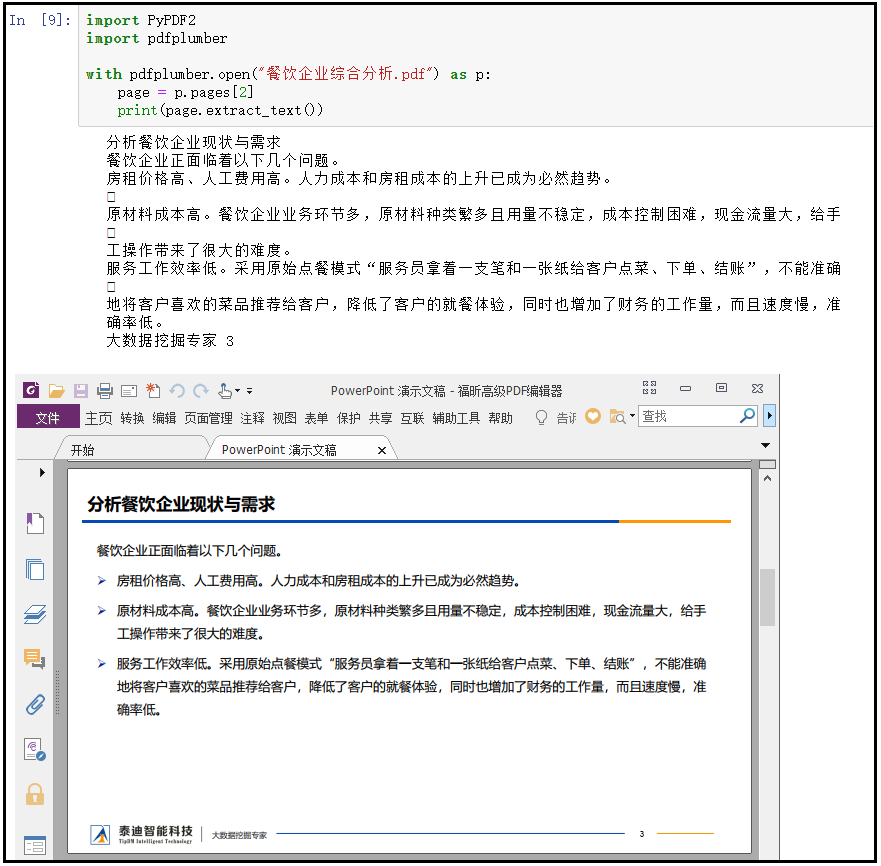 python使用PyPDF2和pdfplumber操作pdf
python使用PyPDF2和pdfplumber操作pdf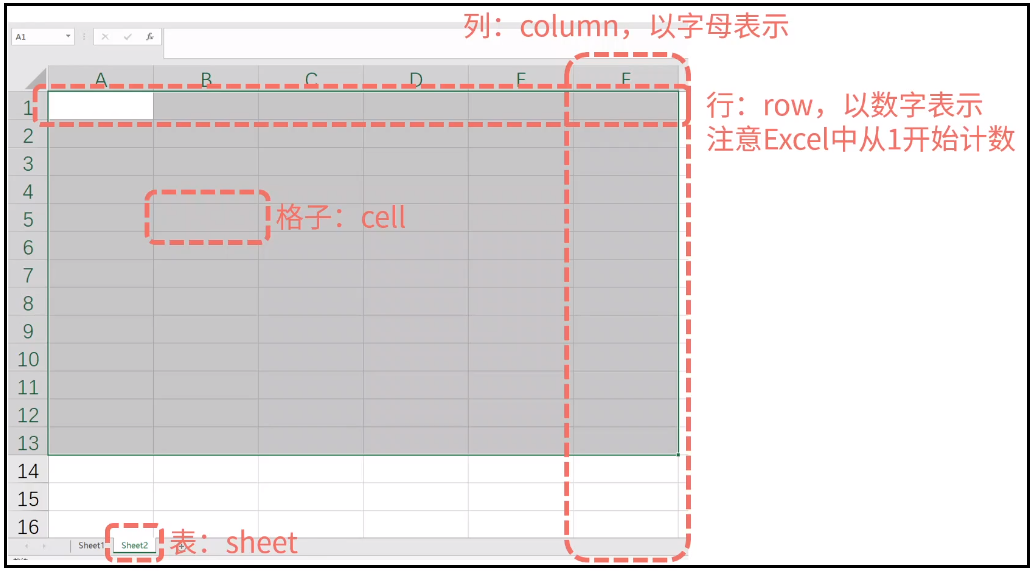 python使用openpyxl操作excel
python使用openpyxl操作excel 配对交易-低风险统计套利量化交易 Python 实战
配对交易-低风险统计套利量化交易 Python 实战