
章节二:python使用PyPDF2和pdfplumber操作pdf
1、PyPDF2和pdfplumber库介绍
- PyPDF2官网: PyPDF2官网 ,可以更好的读取、写入、分割、合并PDF文件;
- pdfplumber官网:pdfplumber官网,可以更好地读取PDF文件内容和提取PDF中的表格;
- 这两个库不属于python标准库,都需要单独安装;
2、python提取PDF文字内容
1)利用pdfplumber提取文字
import PyPDF2
import pdfplumber
with pdfplumber.open("餐饮企业综合分析.pdf") as p:
page = p.pages[2]
print(page.extract_text())
结果如下:
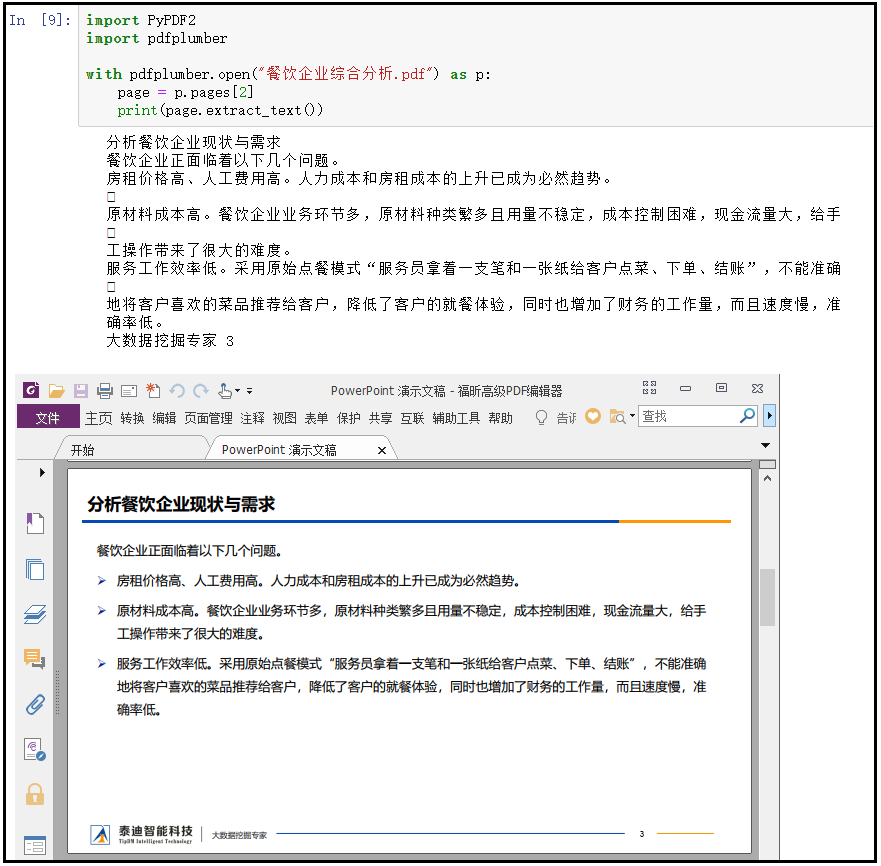
2)利用pdfplumber提取表格并写入excel
- extract_table():如果一页有一个表格;
- extract_tables():如果一页有多个表格;
import PyPDF2
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("餐饮企业综合分析.pdf") as p:
page = p.pages[4]
table = page.extract_table()
print(table)
workbook = Workbook()
sheet = workbook.active
for row in table:
if not "".join() == ""
sheet.append(row)
workbook.save(filename = "新pdf.xlsx")
结果如下:
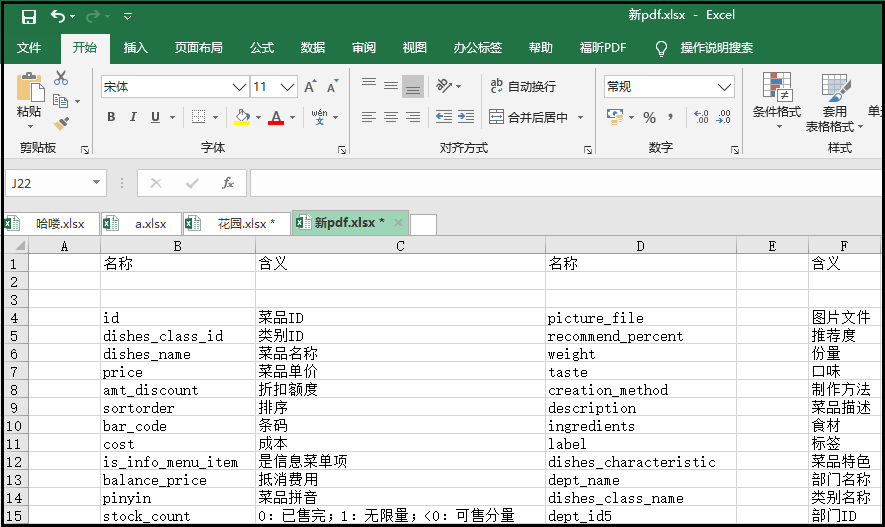
缺陷:可以看到,这里提取出来的表格有很多空行,怎么去掉这些空行呢?
判断:将列表中每个元素都连接成一个字符串,如果还是一个空字符串那么肯定就是空行。
import PyPDF2
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("餐饮企业综合分析.pdf") as p:
page = p.pages[4]
table = page.extract_table()
print(table)
workbook = Workbook()
sheet = workbook.active
for row in table:
if not "".join([str(i) for i in row]) == "":
sheet.append(row)
workbook.save(filename = "新pdf.xlsx")
结果如下:
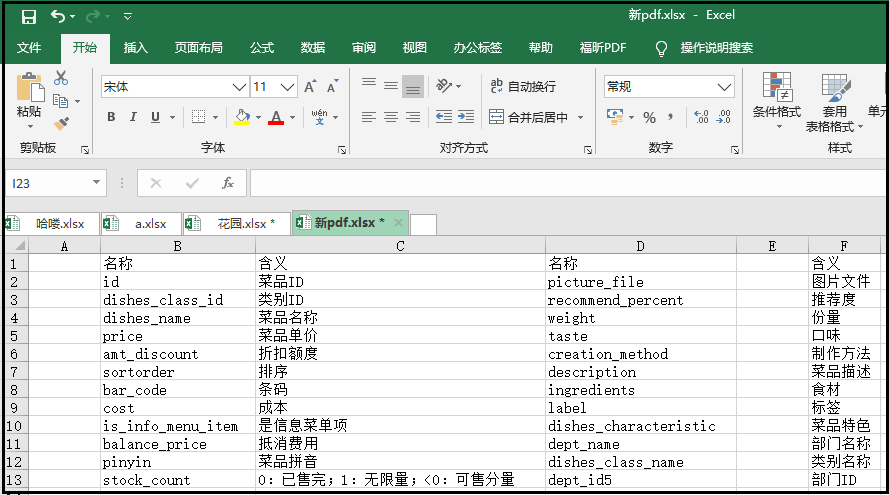
3、PDF合并及页面的排序和旋转
1)分割及合并pdf
① 合并pdf
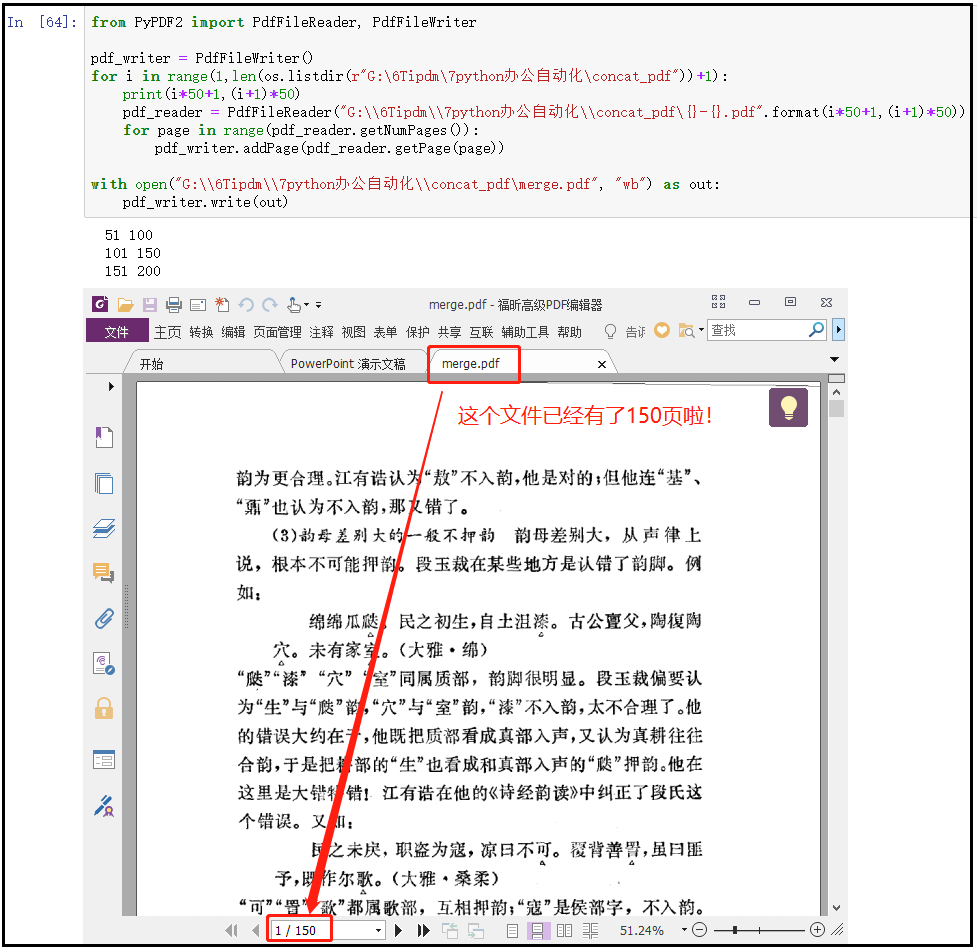
首先,我们有如下几个文件,可以发现这里共有三个PDF文件需要我们合并。同时可以发现他们的文件名都是有规律的(如果文件名,没有先后顺序,我们合并起来就没有意义了。)

代码如下:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_writer = PdfFileWriter()
for i in range(1,len(os.listdir(r"G:\6Tipdm\7python办公自动化\concat_pdf"))+1):
print(i*50+1,(i+1)*50)
pdf_reader = PdfFileReader("G:\\6Tipdm\\7python办公自动化\\concat_pdf\{}-{}.pdf".format(i*50+1,(i+1)*50))
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\merge.pdf", "wb") as out:
pdf_writer.write(out)
结果如下:
② 拆分pdf
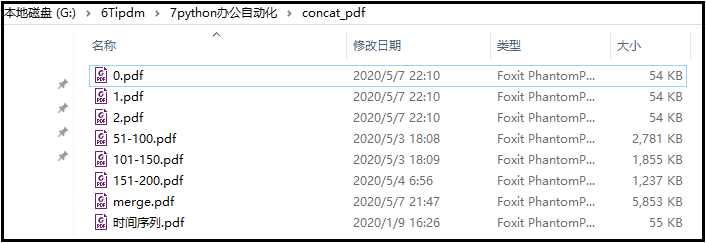
这里有一个“时间序列.pdf”的文件,共3页,我们将其每一页存为一个PDF文件。
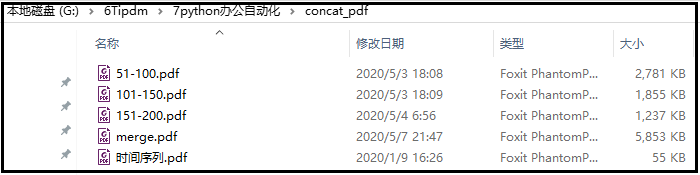
代码如下:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf")
for page in range(pdf_reader.getNumPages()):
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
with open(f"G:\\6Tipdm\\7python办公自动化\\concat_pdf\\{page}.pdf", "wb") as out:
pdf_writer.write(out)
结果如下:
2)旋转及排序pdf
① 旋转pdf
- .rotateClockwise(90的倍数):顺时针旋转90度
- .rotateCounterClockwise(90的倍数):逆时针旋转90度
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf")
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
if page % 2 == 0:
rotation_page = pdf_reader.getPage(page).rotateCounterClockwise(90)
else:
rotation_page = pdf_reader.getPage(page).rotateClockwise(90)
pdf_writer.addPage(rotation_page)
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\\旋转.pdf", "wb") as out:
pdf_writer.write(out)
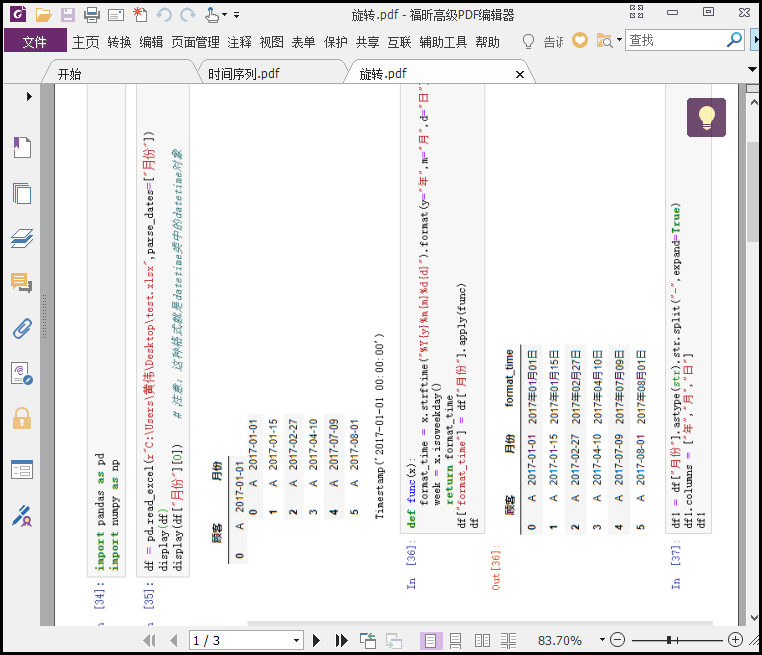
"""
上述代码中,我们循环遍历了这个pdf,对于偶数页我们逆时针旋转90°,对于奇数页我们顺时针旋转90°;
注意:旋转的角度只能是90的倍数;
"""
其中一页效果展示如下:
② 排序pdf
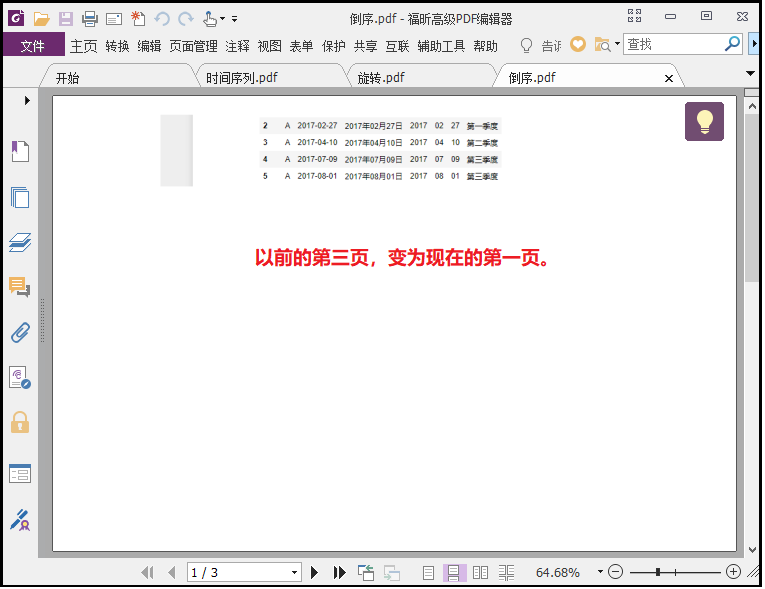
需求:我们有一个PDF文件,我们需要倒序排列,应该怎么做呢?
首先,我们来看python中,怎么倒叙打印一串数字,如下图所示。

那么倒序排列一个pdf,思路同上,代码如下:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf")
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()-1, -1, -1):
pdf_writer.addPage(pdf_reader.getPage(page))
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\\倒序.pdf", "wb") as out:
pdf_writer.write(out)
结果如下:
4、pdf批量加水印及加密、解密
1)批量加水印
from PyPDF2 import PdfFileReader, PdfFileWriter
from copy import copy
water = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\水印.pdf")
water_page = water.getPage(0)
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\aa.pdf")
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
my_page = pdf_reader.getPage(page)
new_page = copy(water_page)
new_page.mergePage(my_page)
pdf_writer.addPage(new_page)
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\\添加水印后的aa.pdf", "wb") as out:
pdf_writer.write(out)
"""
这里有一点需要注意:进行pdf合并的时候,我们希望“水印”在下面,文字在上面,因此是“水印”.mergePage(“图片页”)
"""
结果如下:
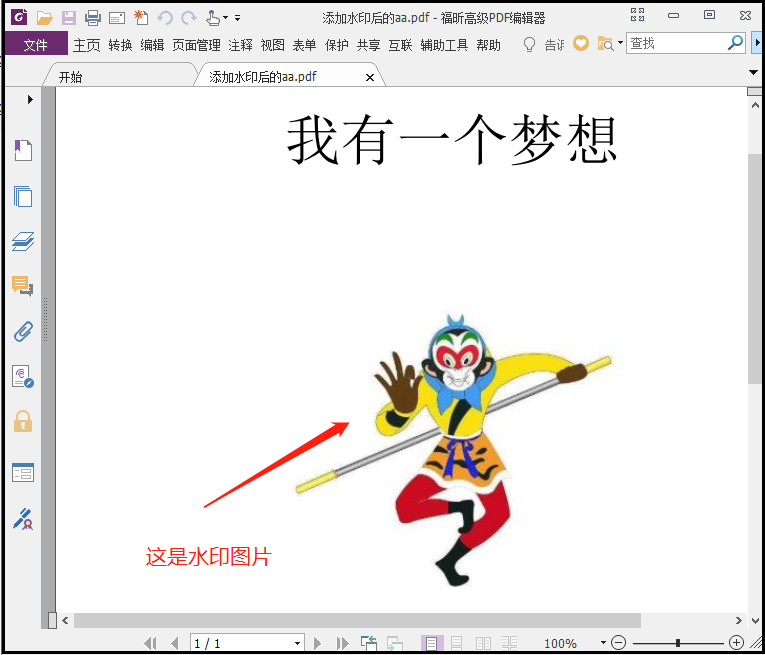
2)批量加密、解密
- 这里所说的“解密”,是在知道pdf的密码下,去打开pdf,而不是暴力破解;
① 加密pdf
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf")
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
# 添加密码
pdf_writer.encrypt("a123456")
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\\时间序列.pdf", "wb") as out:
pdf_writer.write(out)
结果如下:
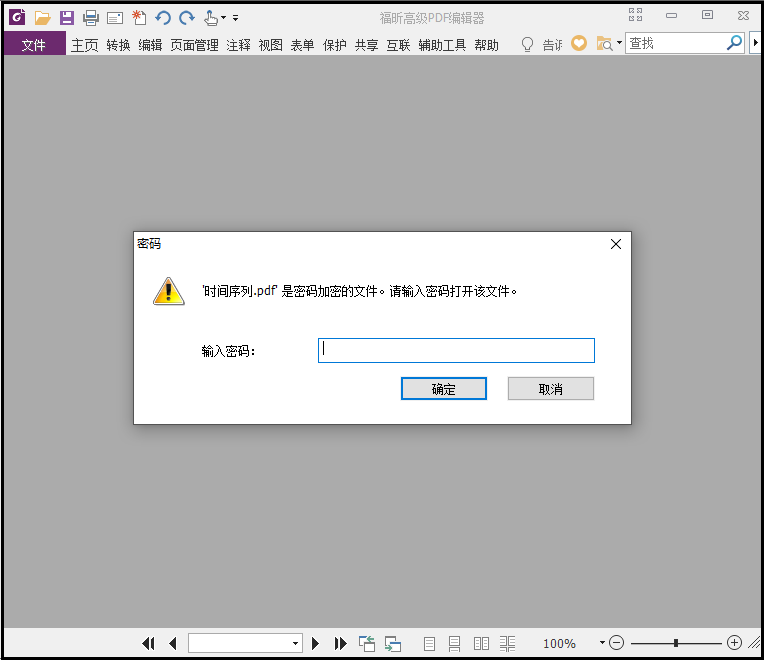
② 解密pdf并保存为未加密的pdf
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"G:\6Tipdm\7python办公自动化\concat_pdf\时间序列.pdf")
# 解密pdf
pdf_reader.decrypt("a123456")
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
with open("G:\\6Tipdm\\7python办公自动化\\concat_pdf\\未加密的时间序列.pdf", "wb") as out:
pdf_writer.write(out)
结果如下:
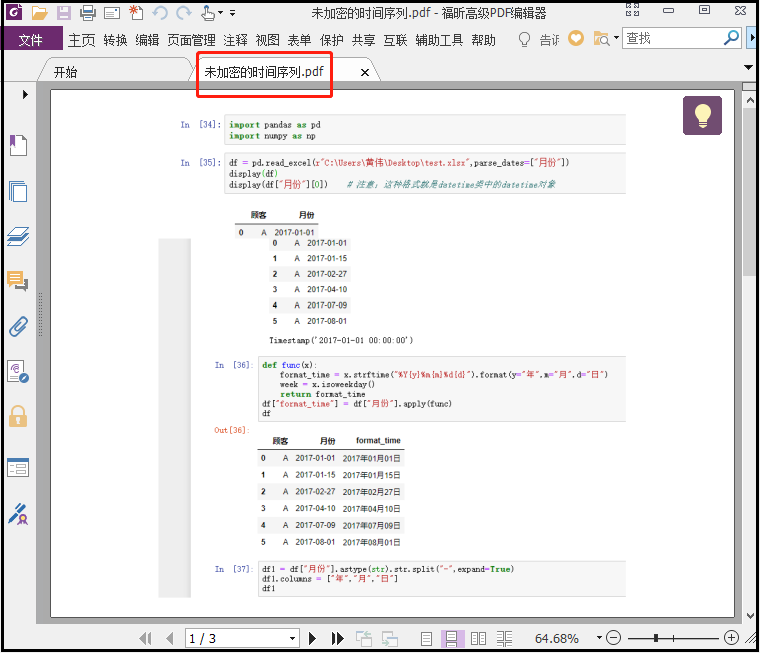
未经允许不得转载:PythonOK » python使用PyPDF2和pdfplumber操作pdf
 python使用python-docx操作word
python使用python-docx操作word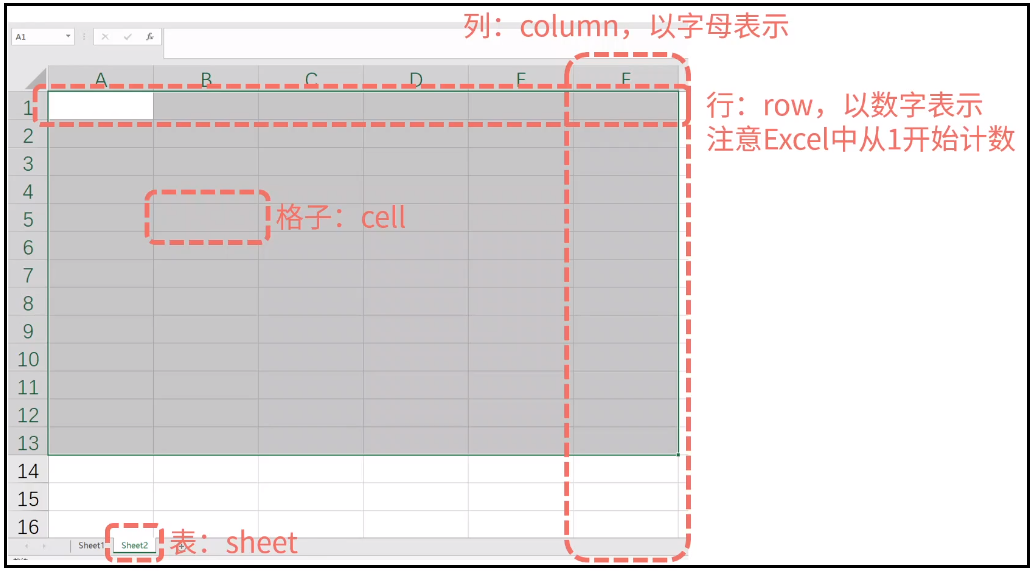 python使用openpyxl操作excel
python使用openpyxl操作excel
 《Think Python》中文版
《Think Python》中文版 Python之路V1.3.pdf
Python之路V1.3.pdf 《Python Cookbook》 3rd Edition pdf 下载
《Python Cookbook》 3rd Edition pdf 下载 关于Python的面试题
关于Python的面试题