
1.9. 朴素贝叶斯(Naive Bayes)
fendouai 发布于 2020-03-04
1.9. 朴素贝叶斯(Naive Bayes) 朴素贝叶斯方法是一组基于Bayes定理的有监督学习算法,在给定类变量(class variable)值的情况下,每对特征之间条件独立的“简单”假设。Bayes定理说明了如下关系,给定类别 y 和相关特征向量x_1到x_n,: \\P...
阅读(609)赞 (0)
fendouai 发布于 2020-03-04
1.9. 朴素贝叶斯(Naive Bayes) 朴素贝叶斯方法是一组基于Bayes定理的有监督学习算法,在给定类变量(class variable)值的情况下,每对特征之间条件独立的“简单”假设。Bayes定理说明了如下关系,给定类别 y 和相关特征向量x_1到x_n,: \\P...
阅读(609)赞 (0)
fendouai 发布于 2020-03-04
处理文本数据 本教程的目的是探索scikit-learn 的一些重要的工具在实际任务:分析有关二十个不同主题的文本文档(新闻帖子)中的使用。 在本节中,我们将看到如何: 加载文件的内容和类别 提取适合机器学习的特征向量 训练线性模型来进行分类 使用网格搜索策略为特征提取器和分类器...
阅读(726)赞 (0)
fendouai 发布于 2020-03-04

统计学习:scikit-learn 中的设置与估计器对象 数据集 Scikit-learn 可以从一个或多个表示为二维阵列的数据集中学习信息。它们可以理解为多维观测数据的列表。这些数组的第一个维度代表样本轴,第二个维度代表特征轴. scikit-learn 附带一个简单示例: i...
阅读(714)赞 (0)
fendouai 发布于 2020-03-04
外部资源,视频和讲座 有关书面教程,请参见文档的教程部分。 Python学习新手? 对于那些仍然不熟悉Python生态系统的人来说,我们强烈建议您使用Python科学讲座笔记。这将帮助您找到立足点,并且肯定会改善您的scikit-learn学习体验。建议充分了解NumPy数组,以...
阅读(696)赞 (0)
fendouai 发布于 2020-03-04
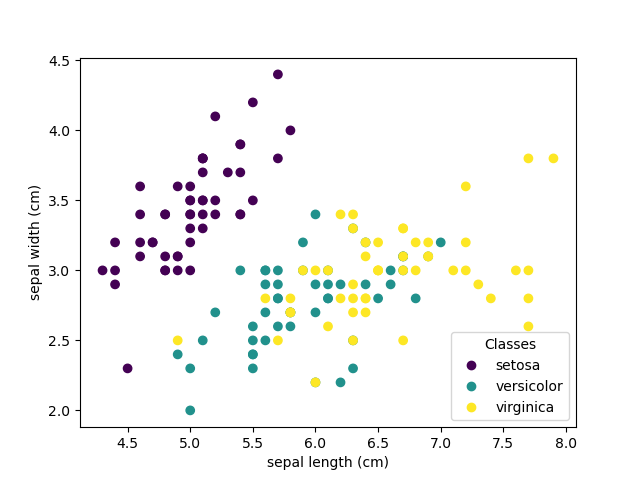
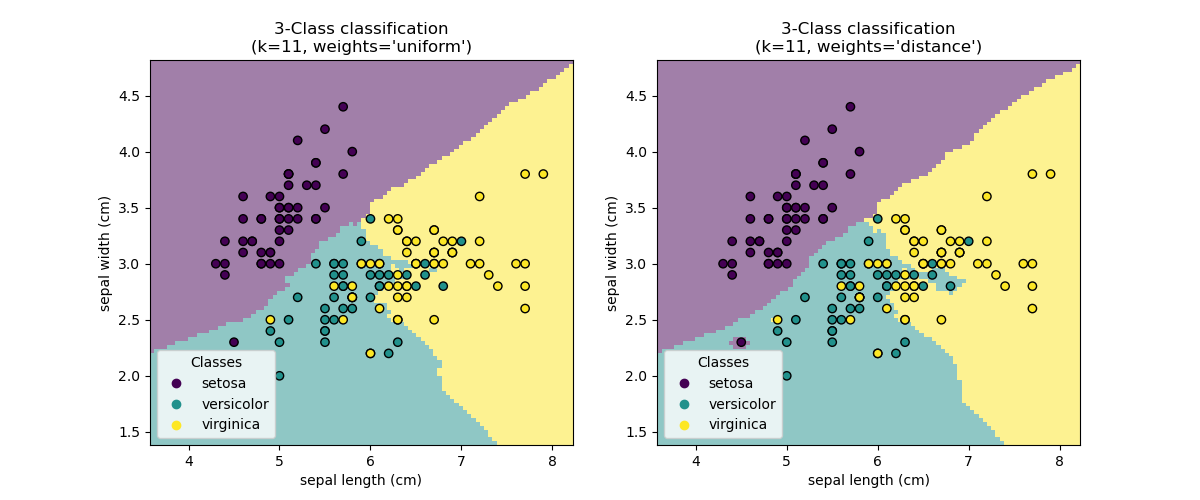
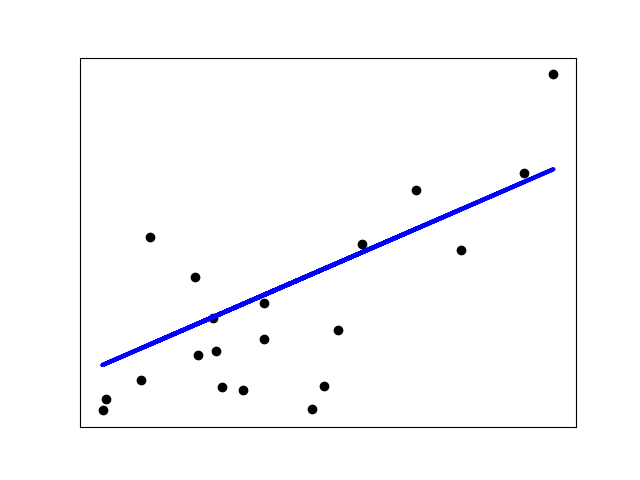
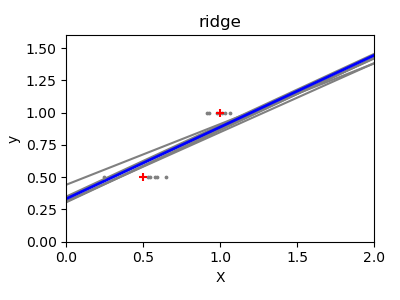
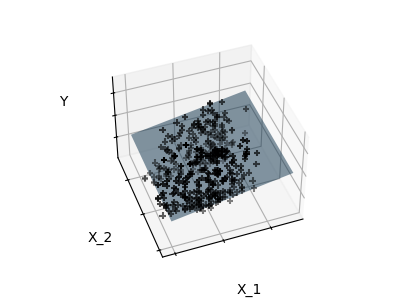
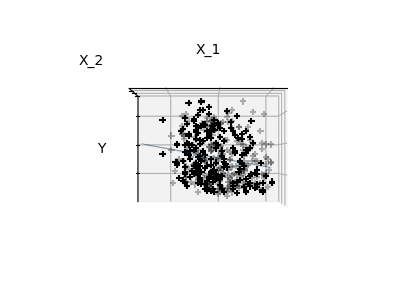
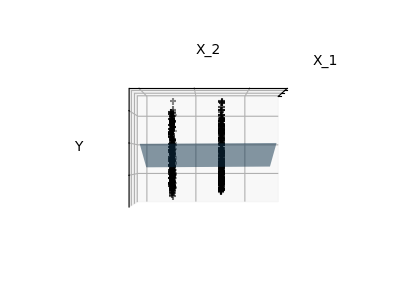
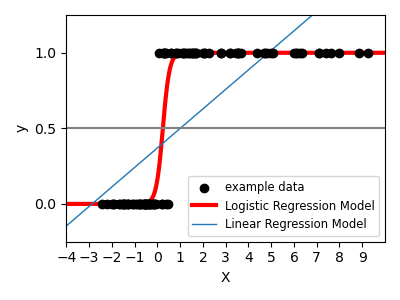
监督学习:从高维数据中预测输出变量 监督学习解决的问题 监督学习 包括学习两个数据集之间的联系:观测数据X和我们试图预测的外部变量y,通常称为“目标”或“标签”。通常情况下,y是长度为n_samples的一维数组。 scikit-learn中的所有有监督估计器都有一个拟合模型的f...
阅读(794)赞 (0)
fendouai 发布于 2020-03-04

把所有的东西集中在一起 管道流 我们已经看到一些估计器可以进行数据转换,一些估计器可以预测变量。我们还可以创建组合估计器同时完成上述任务: import numpy as np import matplotlib.pyplot as plt import pandas as pd...
阅读(617)赞 (0)
fendouai 发布于 2020-03-04


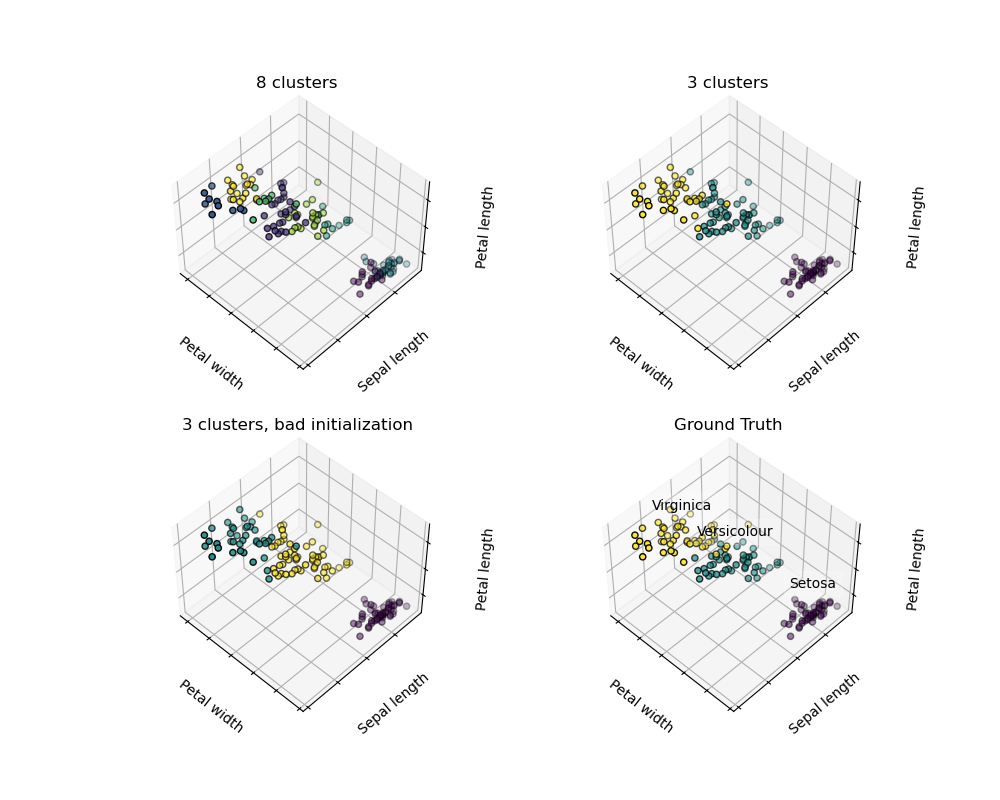

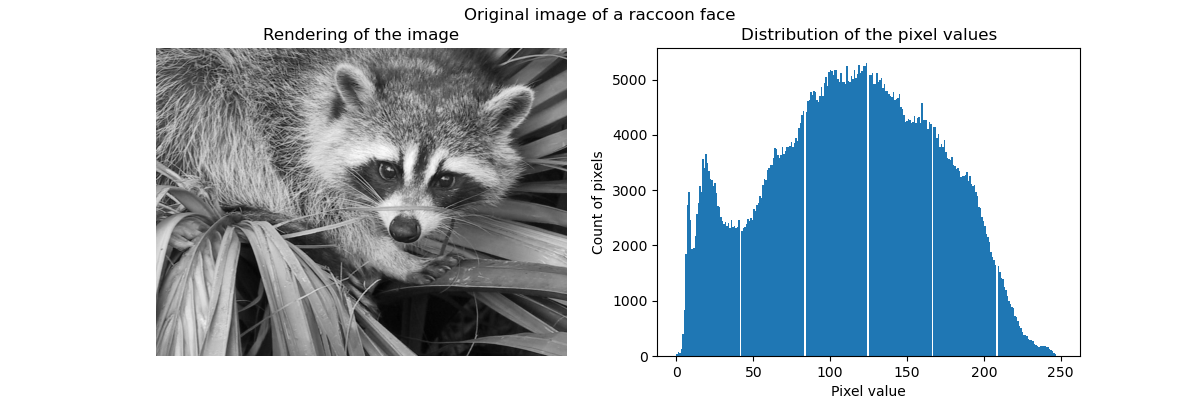
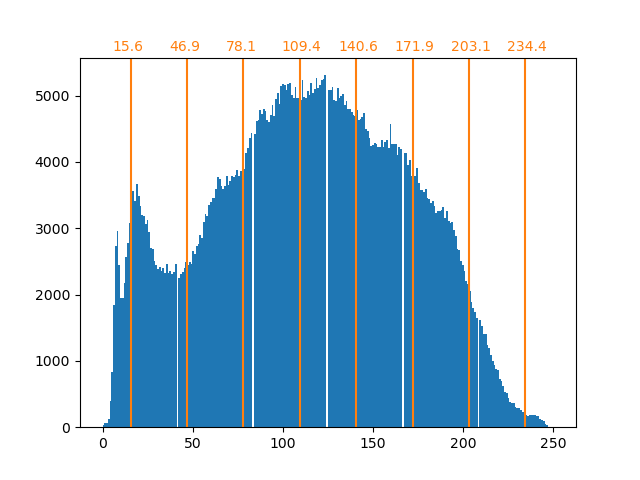
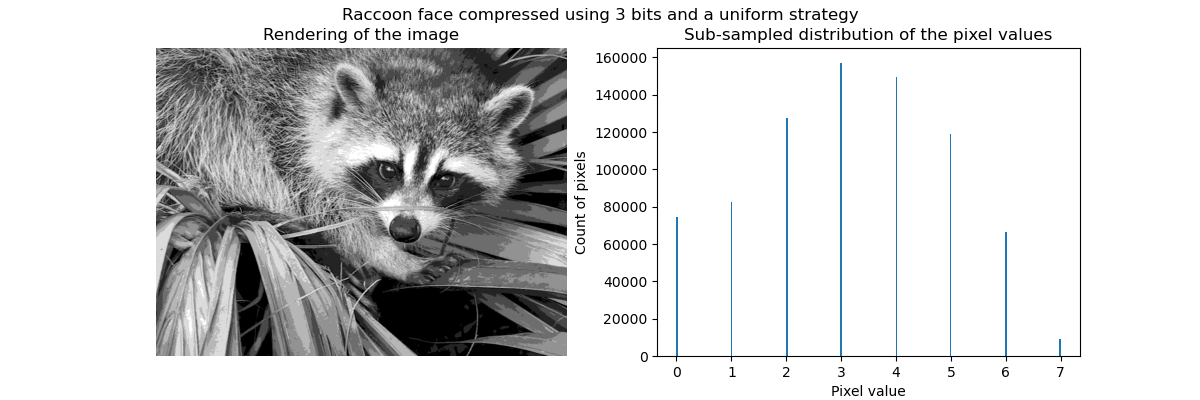
无监督学习:寻求数据的表示形式 聚类:对观察数据进行分组 聚类解决的问题 对于鸢尾属植物数据集来说,我们知道鸢尾属植物有3种不同的类型,但是并不知道每一个样本是那种类型:我们可以尝试 聚类任务:将样本数据分为不同的组,不同组之间是有明显差距的。这样的算法称为clusters(聚类...
阅读(729)赞 (0)
fendouai 发布于 2020-03-04
科学数据处理统计学习指南 统计学习 随着科学实验数据规模的迅速增长,机器学习成为了一种越来越重要的技术。 它解决的问题从建立链接不同观测数据的预测函数,到对观测数据进行分类或从未标记数据集中学习到一些结构。 本教程将探讨使用机器学习技术进行统计推断的统计学习的使用:从手中的数据上...
阅读(726)赞 (0)
fendouai 发布于 2020-03-04
scikit-learn机器学习简介 章节内容 在本节中,我们将介绍在scikit-learn中所使用的机器学习的词汇,并且给出一个简单的代码示例。. 机器学习:问题设置 通常,一个机器学习问题会考虑n个数据样本,然后尝试预测未知数据的属性。如果每个样本都不止一个属性的话,例如是...
阅读(596)赞 (0)
fendouai 发布于 2020-03-04
寻求帮助 项目邮件列表 如果您在使用scikit-learn中遇到文档字符串或在线文档中的错误或需要澄清的内容的话,请随时在邮件列表中询问。 机器学习实践者问答社区 Quora.com: Quora有一个与机器学习相关的问题的主题,其中还包含一些有趣的讨论:https: //ww...
阅读(1434)赞 (0)